
DNA 版本的隨機存取技術
DNA 被看作更輕便、保存時間更長的數字信息存儲載體,技術進展很快。
電影、GIF 動圖、文學名著《戰爭與和平》都被放入到 DNA 上,存儲的數據規模也越來越大。
技術層面,在 DNA 上存儲、解碼數字信息是這樣的:研究員需要把數據從 0 和 1 轉換成形成 DNA 的堿基:腺嘌呤(A)、胸腺嘧啶(T)、鳥嘌呤(G)、胞嘧啶(C),再通過合成 DNA 存儲這部分的數據。
當數據需要被取回時,研究員通過對 DNA 進行測序,將數據重新從堿基還原成 0 和 1。
隨著數據存儲規模的擴大,相應的,確定 DNA 上存儲數據的位置,以及還原數據的技術也在跟進。
微軟最近和華盛頓大學的分子信息系統實驗室(MISL)合作,開發了新的檢索 DNA 序列、解碼的技術。
他們將 35 個文件、總共 200.2 MB 的數據存儲到了 1300 萬的 DNA 寡核苷酸(只有 20 個以下堿基的短鏈核苷酸)上,並成功在一個有 1030 萬條 DNA 序列的池裏找到、解碼這些數據,中間沒有發生數據丟失。
這些研究員選擇存儲在 DNA 上的數據包括下列這些:OK Go 樂隊的歌曲 This Too Shall Pass 的高清 MV、經典音樂精選集,《世界人權宣言》的 100 種語言版本、CropTrust 存儲了斯瓦爾巴全球種子庫的數據庫等。
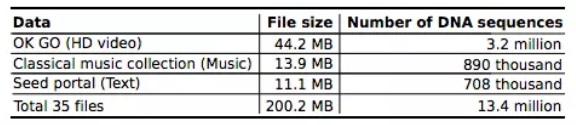
存儲了 200.2 MB 的數據到 DNA 上
該論文發表在《自然-生物技術(Nature Biotechnology)》期刊上,微軟官網也附上了該論文。
他們使用的是一種被稱為“隨機存取(random access)”的技術。
這不是新技術,但微軟和 MISL 實驗室在使用的數據量和解碼準確度上都有所提升。
所謂的 DNA 數據隨機存取,類似於電腦、手機在調取照片、歌曲時所用的 RAM 技術。
略有差別的地方在於,電腦、手機在調用數據時,這些數據存儲的位置不影響調用速度,而且調用速度很快。
但在 DNA 上取回數據,暫時只能做到存儲位置不影響,解碼數據的速度還沒能提升。
取回 DNA 上存儲數據上的一般流程是這樣的,解開 DNA 雙螺旋結構、複製儲存數據的序列,然後轉換這些數據。
為了獲得所需數據,常常需要對整條 DNA 進行測序。
DNA 上的隨機存取技術,通常是引物庫(引物指一小段 DNA 或 RNA)配合聚合酶鏈式反應(PCR)一起使用。
加在每個 DNA 序列的兩端的引物可以幫助更快確定數據存儲的位置,在解碼時,研究員不需要對整條 DNA 進行測序,PCR 通過反覆複製想讀的序列幫助加快解碼速度。
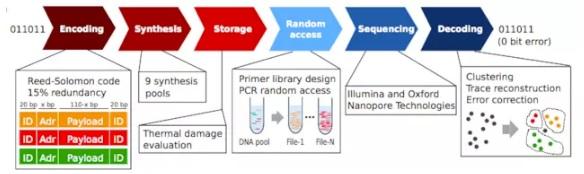
DNA 上隨機存取的流程
在微軟和 MISL 實驗室的實驗中,研究員設計了新的引物庫,解碼、還原數據的算法,增加了儲存、解碼數據時的容錯能力,最終在取回數據時沒有出現數據丟失。
解碼器和算法開發這方面上有微軟比較多的貢獻。
微軟和華盛頓大學在 DNA 存儲、解碼數據的技術上合作了多個項目,微軟的研究員 Karin Strauss 也是領導 MISL 實驗室的管理者之一。
例如 2016 年,兩家公司合作,把《戰爭與和平》等 100 部經典作品塞進了 DNA 內。
這算是微軟對未來存儲技術看中的方向之一,例如用 DNA 取代數據中心裏的硬碟。
Karin Strauss 曾說:“公司有興趣了解,我們是否能創造一種、端到端、自動化、可用於企業存儲、基於 DNA 的信息存儲系統。”
作為存儲介質,DNA 相比硬碟、TF 卡等都要輕便,保持在乾燥、較低氣溫環境下,可以保存很久,這些都是優勢。
但 DNA 合成成本、花費的時間成本都相當高昂。
微軟存儲 100 部經典作品、總共 200 MB 的數據到 DNA 上,花費了 15 億個堿基,以 Twist Bioscience 針對企業用戶每個堿基賣 0.04 美分計算,也需要 6000 萬美元。
加州大學伯克利分校的博士後研究員 Reinhard Heckel 認為,雖然這項技術的成本在持續降低,但能否低於磁帶還很難說:“為了讓人們真正用起來,你需要把東西存儲在比磁帶更便宜的載體上,這是很難的。”
資料來源:source
沒有留言:
張貼留言